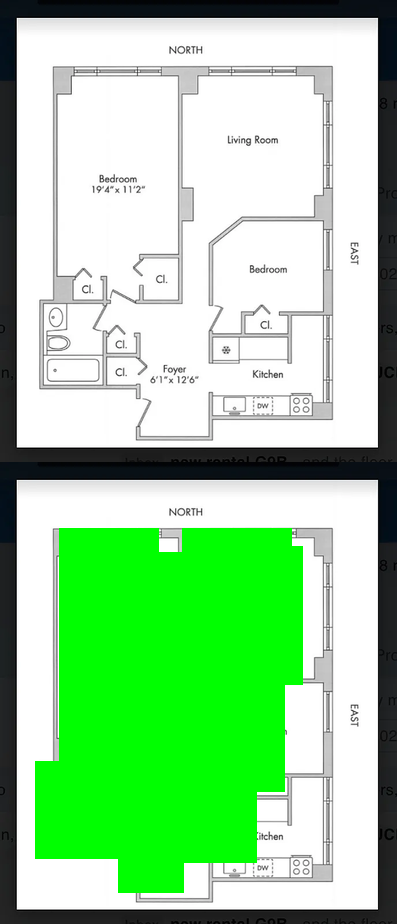
Floor plan area micro-eval
I made an LLM agent micro-eval where I asked the agent to compute the square footage of an apartment given a floor plan of the apartment. This involved two steps: determining the scale of the floor plan by looking at room dimension labels (e.g. 20’ x 12’), and marking the parts of the floor plan that count as square footage (interior areas and exterior walls, but not exterior areas like balconies).
I evaluated GPT-5.5 in Codex CLI and Claude Opus 4.8 and Fable 5 in Claude Code CLI on a set of 15 floor plans. I did 4 runs with each agent, and each run processed all 15 input images. I manually made ground truth outputs for each floor plan.
GPT-5.5 achieved an average error of 23.2%, Claude Opus 4.8 achieved 13.2%, and Claude Fable 5 achieved 6.5%. The error was mostly due to mis-estimating the scale and less due to mis-marking the interior area (the error was >70% from scale and <30% from marking for all three agents). This accuracy exceeded my expectations, but I would still not trust current agents with this work if I needed good accuracy.
Code for this project is here.
Output format
I asked the agents to make output images like this, where the interior areas are marked in green and the image is scaled to 1 ft per 10 px, so that the floor area can be measured by counting the green pixels.

Results
| model | GPT-5.5 | Opus 4.8 | Fable 5 |
|---|---|---|---|
| harness | Codex | Claude Code | Claude Code |
| scale MAE (log10 space, 2D) | 0.0861 | 0.0511 | 0.0258 |
| marked area mean IOU | 0.9034 | 0.9502 | 0.9737 |
| marked area MAE (log10 space) | 0.0232 | 0.0139 | 0.0076 |
| final area MAE (log10 space) | 0.0906 | 0.0539 | 0.0273 |
Note that the scale MAE calculation is 2D rather than 1D: a 10% scale error along 1 dimension translates to an error of log10(1.1 ** 2) = 0.0828 in 2D log10 space.
Commentary
Each run processed all 15 inputs, and the agents generally used a similar strategy for all 15 inputs within a single run. This means that the errors within a run are correlated with each other; if the agent picked a poor strategy during that run, all estimates would be off. This correlation means the error estimates themselves have higher error bars than we would naively expect given the sample size. GPT 5.5 was especially affected by this; its per-run final area MAE ranged from 0.0447 (run 1) to 0.1522 (run 2) log10 units, whereas Claude Opus 4.8 was more consistent, ranging from 0.0444 (run 4) to 0.0612 (run 3).
The floor plan with the greatest overall computed area error was this one from Codex, where the estimate was 2.5x the true value. This input has an erroneous dimension: it should say about 10’10” instead of 20’. Other runs from Codex and Claude were not tripped up by this.
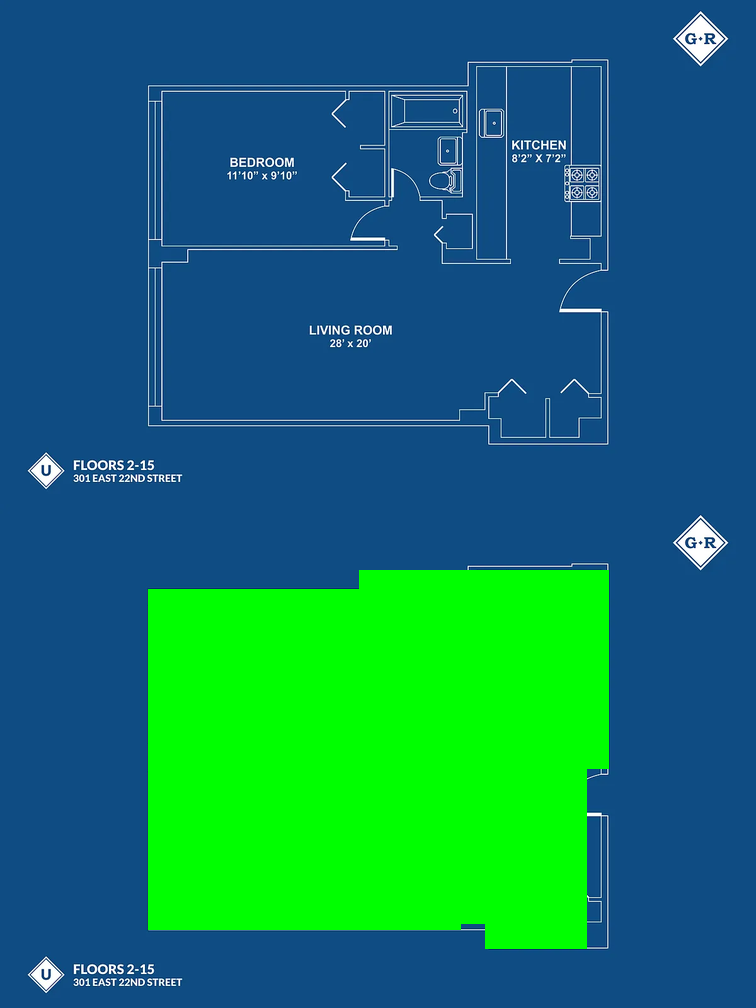
The floor plan with the greatest marked area error was this one from Codex, where the marked area was 32% too large. I’m not sure what happened; this is a very easy input where the solution is just a rectangle, but it drew a rectangle that was too wide.

A more interesting failure was this floor plan from Codex, where it failed to mark 20% of the floor plan.